


EasyVista, a global SaaS provider for comprehensive IT service management (ITSM), IT monitoring, Enterprise Service Management, and Remote Support, today announced the launch of EV Pulse AI, a transformative AI layer integrated into its flagship EasyVista Platform. These major enhancements to EasyVista’s AI capabilities, part of the Platform 2024.3 release scheduled for November 2024, represent a significant enrichment of EasyVista’s AI capabilities, offering organizations unprecedented power to simplify IT complexities, streamline operations, and accelerate digital transformation.
Perforce’s Helix Core Now ISO 26262 Certified for Functional Safety in Automotive Development

2024 Data Protection Trends Report: Key Insights and Implications
As we move into Q2 2024, data protection remains a critical area of focus for organizations worldwide. The “2024 Data Protection Trends Report” by Veeam Software provides a comprehensive analysis of the current landscape and future directions in data protection.
This report is based on insights from over 1,200 unbiased IT leaders and implementers in 10 countries who are leading data protection strategies for enterprise organizations of various sizes. The report had four agenda items: What are IT leaders thinking about? Where does the cloud fit? Cyber continues to be ‘when’ not’ if, ‘ and most are not ready for a disaster. Below is an overview of the report.

Increasing Investment in Data Protection
One of the report’s standout findings is the increasing investment in data protection. Organizations are expanding their IT budgets and allocating a larger portion specifically to data protection. According to the survey, 92% of organizations are increasing their data protection budgets, and protection budgets are expected to grow by 6.6%.
This trend underscores the growing recognition of data as a critical asset that needs robust protection systems. As cyber threats become more sophisticated and pervasive, the need for advanced data protection solutions becomes a top priority.
Summary of the Data Protection Trends Report
Centralized vs Decentralized Data
With data emerging as a critical asset for businesses, adopting centralized or decentralized data storage strategies becomes increasingly crucial. Each approach has its own perks and drawbacks, shaping how data is stored, managed, accessed, and utilized. Centralized data promises consistency and efficient management, while decentralized data offers fault tolerance and improved scalability. But which approach is most suitable for your organization?
In this article, we will explore centralized and decentralized data, their pros and cons, and guide you toward choosing the most suitable one for your organization.

What is Centralized Data?
Centralized data involves gathering data from different sources and storing it in one central database, warehouse, and data lake. The data repository offers a centralized point for managing, storing, and using data, allowing for easier maintenance and management of data.
Advantages of Centralized Data
Data centralization comes with several perks. They include:
- Efficient Data Management
It’s easier to manage data using a single source of truth. It allows administrators to manage and regulate data, reducing confusion and redundancy in data management efforts.
- Data consistency
A centralized repository ensures that data is consistent across the organization. When there’s access to a single storage unit, every user in the organization has access to the same data, reducing the risk of conflicts.
- Improved Data Analysis
A centralized data repository supports improved data analysis by providing easy access to various data types. This accessibility enables businesses to gain deeper insights and informed decision-making across the organization.
- Robust Security Measures
Centralized data offers a single entry point, making managing and monitoring access controls, encryption, and compliance measures easier. Thus, there is less of a risk of unauthorized access or breaches.
Disadvantages of Centralized Data
Below are some drawbacks of centralized data:
- Data Silos
Centralized data can lead to data Silos where different departments may hoard data, leading to inaccessibility from other teams. This can frustrate collaboration efforts and make it difficult for users in various departments to gain holistic insight.
- Loss of Context
Centralization may lead to a loss of context as different departments or domains have unique perspectives on data. Attempting to fit diverse data contexts into a single system can lead to oversimplification or misrepresentation of information, making it difficult to understand data and make informed decisions.
- Single Point of Failure
Using a single source of truth is risky because it introduces a single point of failure. Thus, if a power failure, technical issue, or cyber attack leads to data loss, the entire dataset is more likely to be corrupted, compromised, or even lost. Robust data recovery plans are essential to prevent such loss.
- Privacy Issues
Centralized data can pose privacy concerns in an organization. A centralized data system doesn’t guarantee privacy when dealing with sensitive information or customer data. Thus, organizations using this method must implement privacy protocols to keep customer information private.
- Rigid Decision-Making Processes
The reliance on centralized data sources can lead to rigidity in decision-making processes. Decision-makers may become dependent on predefined datasets, limiting their ability to adapt to evolving business needs or explore alternative perspectives. This rigidity can hinder innovation and responsiveness to market changes.
What is Decentralized Data?
Decentralized Data involves the storage, cleaning, and use of data in a decentralized way. That is, there is no central repository. Data is distributed across different nodes, giving teams more direct access to data without the need for third parties.
Advantages of Decentralized Data
The advantages of choosing decentralized data are:
- Increased Data Autonomy
Decentralization grants autonomy to individuals or departments, fostering a sense of ownership and accountability over data. This empowerment encourages innovation and experimentation, as teams can customize their data management practices to suit their unique needs better.
- Improved Scalability
Decentralized data supports scalability, enabling data distribution across multiple nodes. Hence, organizations can effortlessly scale their infrastructure to accommodate growing data volumes or expand operations without facing the restrictions of centralization.
- Data Localization
Decentralization enables organizations to store data closer to users or within specific geographic regions. For large organizations that cut across geographical landscapes, a decentralized data approach allows them to comply with regional data privacy regulations, which may prove difficult when using centralized data.
- Resilience and Fault Tolerance
When decentralized, data is also more resilient against system failures and cyber-attacks. This redundancy minimizes the risk of data loss or service disruption due to a single point of failure. With data distributed across multiple nodes, a failure of one node will not affect others, allowing operations to continue in other departments. Hence, business operations and data availability will be largely uninterrupted.
Disadvantages of Decentralized Data
- Data Consistency Issues
Maintaining data consistency across multiple decentralized nodes can be challenging, leading to misinformation or inaccurate data interpretation. However, using robust synchronization mechanisms can help ensure data remains accurate and up-to-date across the network, preventing conflicts or inconsistencies.
- Complex Data Integration
Data integration is also time-consuming because of the complexities associated with decentralization. Thus, data interoperability and compatibility between different nodes are crucial to ensure seamless data exchange and integration.
- Increased Security Risks
With decentralized storage, the task of securing data becomes greater. With data spread across different nodes, an organization must provide adequate protection for each node to prevent unauthorized access or tampering. Robust systems like encryption, access controls, and authentication mechanisms can offer high security and reduce the risk of cyber threats.
Choosing Between Centralized or Decentralized Data
Making a choice between centralized and decentralized data storage requires a critical evaluation of your organization’s specific needs and objectives. While centralized storage offers enhanced analytics, consistency, and efficient data management, decentralized storage offers scalability, data ownership, and fault tolerance.
Besides their advantages, you must also consider the disadvantages of each data storage method. Centralized storage can lead to a single point of failure, privacy issues, and data hoarding. On the other hand, decentralized storage can increase security risks and lead to data inconsistency.
However, in practical applications, most organizations use hybrid models that combine both strategies, enabling them to leverage the benefits of both systems. No matter your approach to data management and storage, it’s crucial to employ robust disaster recovery, backup, and cyber security measures to protect your data from corruption or loss.
Storware for Centralized and Decentralized Data
Storware Backup and Recovery offers functionalities that can be useful for protecting both centralized and decentralized data:
Centralized data protection: Storware can be used to backup data on physical servers, which are often centralized storage systems for businesses. It allows for agent-based file-level backups for Windows and Linux systems, including full and incremental backups. This ensures that critical data stored on central servers is protected.
Virtual environment protection: Storware also offers backup and recovery solutions specifically designed for virtual environments like VMware vCenter Server and ESXi standalone hosts. This enables users to protect virtual machines and container environments, which are becoming increasingly common for hosting decentralized applications and data.
Overall, Storware provides a way to secure both traditional centralized data storage and the newer, more distributed world of virtual machines and containers.
Here are some additional points to consider:
- Scalability and manageability: Storware is a scalable solution that can grow with your business needs. This is important for organizations with ever-increasing data volumes.
- Security features: Storware offers features like encryption and access control to safeguard your data from cyberattacks, ransomware, and human error.
For a more in-depth understanding of how Storware can address your specific data protection requirements, it’s recommended to check our official resources or contact our sales team.
Conclusion
While centralized storage offers security, data consistency, and improved data analysis, decentralized storage offers scalability, data autonomy, and fault tolerance.
Choosing between centralized and decentralized data is not a one-side-fits-all decision. Hence, organizations should adopt hybrid methods that find the right balance between both approaches. This will allow you to get the best of both worlds and offset their disadvantages.
RTO and RPO – Explanation of Concepts
In an increasingly digital and interconnected business environment, the terms “RTO” and “RPO” are pivotal for ensuring the survival of any organization when disaster strikes. Recovery Time Objective (RTO) and Recovery Point Objective (RPO) might sound like mere technical jargon, but they hold the key to a business’s ability to bounce back from disruptions.
However, it’s not just about responding to adversity; it’s about safeguarding your enterprise’s integrity, reputation, and sustainability. By deciphering the differences between these two terms, you can tailor your recovery plans to ensure a seamless return to normalcy while minimizing data loss.
This guide explores RTO and RPO, shedding light on their definitions, distinctions, and the critical role they play in crafting foolproof disaster recovery strategies.

Definition of RTO
Think of RTO as the stopwatch that starts ticking when a system fails. The clock is set according to the business’s unique needs and priorities. RTO stands for “Recovery Time Objective,” a crucial element in disaster recovery planning. It refers to the maximum acceptable downtime for a business process or application after a disaster or disruption occurs. Essentially, RTO indicates the amount of time a process can remain unavailable before it starts to affect the business adversely. For instance, if a business process has an RTO of 2 hours, it means that after a disaster strikes, the organization must ensure that the process is up and running within 2 hours to avoid significant negative impacts on operations, customer satisfaction, or financial performance. Different business processes have varying RTO values based on their criticality to the organization. High-priority processes like e-commerce transactions or financial transactions might have lower RTO values, often in minutes to a couple of hours. On the other hand, less critical processes, such as internal reporting systems, could have higher RTO values, ranging from several hours to even days. Setting appropriate RTO values requires a careful assessment of the potential impact of downtime on different processes and the organization as a whole. It helps you prioritize your resources and efforts in disaster recovery planning to minimize disruptions and maintain smooth operations.Definition of RPO
While RTO focuses on the “when” of recovery, the Recovery Point Objective (RPO) homes in on the “what.” It signifies the maximum acceptable amount of data loss a business can tolerate during a disruption or disaster. In essence, RPO defines the point in time to which data restoration must occur after recovery efforts, representing the extent of data rollback without causing unacceptable damage to business operations. RPO measures how much data the organization will lose in the recovery process. For example, suppose a business has an RPO of 1 hour. In that case, it means that after a disruption, the data restoration can only be to a point in time that is no more than 1 hour before the incident occurred. Any data changes made within that hour might be lost. Choosing appropriate RPO values is crucial to align backup and recovery strategies with your business needs. More critical data requires smaller RPO values to minimize loss, while less critical data may tolerate longer intervals. RPO helps you balance data protection and the cost and complexity of implementing backup solutions.RTO vs. RPO: Key Differences
While RTO and RPO might appear as two sides of the same coin, they hold distinct purposes. Below are some key differences between RTO and RPO: Focus- RTO focuses on downtime or the time it takes to restore a business process or application after a disruption. It indicates the acceptable maximum duration a process can be unavailable.
- Meanwhile, RPO concentrates on data loss or the maximum amount of data that can be lost during the recovery process. It defines the point in time to which the restoration of data needs to occur.
Striking the Balance Between RTO and RPO
When designing your disaster recovery plans, you must consider RTO and RPO. Business continuity and disaster recovery planning are complex tasks that require a comprehensive approach. You can ensure a holistic recovery strategy by considering both RTO and RPO. While an organization may have low downtime tolerance (short RTO) for a critical e-commerce platform, it may also need minimal data loss (small RPO) for financial data. Conversely, a longer RTO might be acceptable for an internal reporting system. However, there’s still a need to limit data loss. Striking the right balance between RTO and RPO involves understanding the criticality of different business processes and data types. This enables you to allocate resources effectively and choose appropriate recovery solutions, such as high-availability systems, redundant data centers, and frequent data backups. By addressing downtime and data loss concerns, you can enhance your business’s ability to recover swiftly and maintain essential operations despite unexpected disruptions.Factors Influencing RTO and RPO
Determining the optimal values for RTO and RPO is not a one-size-fits-all endeavor. A multitude of factors come into play, shaping the decisions of your business as you tailor your disaster recovery strategies. Business Requirements The nature of your business and its processes directly influences acceptable downtime and data loss. High-stakes industries like finance or healthcare may necessitate aggressive RTO and RPO values due to the immediate consequences of disruptions. Technology Capabilities Your IT infrastructure’s capabilities play a pivotal role. Modern technology allows for real-time data replication and swift failover mechanisms, reducing downtime and data loss. However, the advanced solutions required might come at a cost that smaller businesses find challenging to bear. Budget Constraints Every strategic decision in business inevitably hangs on budget considerations. Investing in cutting-edge recovery solutions might be feasible for larger enterprises but not viable for smaller ones. Therefore, setting RTO and RPO values should align with the available financial resources. Balancing these factors is crucial for finding the optimal combination of RTO and RPO values that align with the organization’s needs, technological capabilities, and budgetary constraints while ensuring business continuity and data protection.Best Practices for Determining RTO and RPO
Crafting effective RTO and RPO values requires a nuanced approach that mirrors the uniqueness of each business. Here are some best practices to consider: Understand Business Objectives and Priorities- Assess the criticality of various business processes and data types. Consider factors like revenue impact, customer satisfaction, compliance requirements, and legal obligations.
- Align RTO and RPO values with your business objectives. High-priority processes and data should have lower values to minimize disruption and data loss.
- Evaluate potential risks and their impact on your business operations. Identify possible scenarios that could lead to downtime or data loss.
- Consider historical data and industry benchmarks to estimate the probability and consequences of different types of disruptions.
- Engage stakeholders from IT, operations, finance, and management to gain diverse perspectives on acceptable levels of downtime and data loss.
- Collaborate to strike a balance between technical feasibility and business needs.
- Understand your organization’s technical capabilities regarding backup frequency, recovery speed, and available resources for disaster recovery.
- Choose technologies and solutions that can meet the determined RTO and RPO values.
- Recognize that business needs evolve over time. As your business grows, changes its processes, or faces new risks, regularly reassess and adjust RTO and RPO values accordingly.
- Conduct periodic tests and simulations to validate the effectiveness of your disaster recovery strategy.
- Evaluate the costs of achieving shorter RTO and RPO values against the potential benefits of reduced downtime and data loss.
- Make informed decisions based on a balance between operational requirements and budget constraints.
- Document your disaster recovery plan’s determined RTO and RPO values with utmost clarity.
- Ensure that all relevant stakeholders, including IT teams and management, understand the objectives and priorities behind these values.
- Regularly test your disaster recovery plans in realistic scenarios to identify gaps and refine your strategies.
- Use test results to iterate and optimize your recovery processes, adjusting RTO and RPO values if necessary.
Protecting Your Business with Informed Recovery Planning
Recovery Time Objective (RTO) and Recovery Point Objective (RPO) take center stage in this intricate necessity of business continuity. Understanding the essence of these concepts empowers businesses to make informed decisions when adversity strikes. Remember, it’s not just about recovering—it’s about recovering strategically. By aligning RTO and RPO values with your unique circumstances, you fortify your business against disruptions while maintaining data integrity. As you embark on crafting and refining your disaster recovery strategy, remember that it’s a continuous process. The ever-changing business landscape demands adaptability, ensuring that your RTO and RPO values remain steadfast pillars of resilience.Backup for Structured and Unstructured Data
Data protection requires administrators to consider several important issues. The type of data, its location, and growing capacity requirements are of key importance.

The division of data into structured and unstructured data has existed for many years. Interestingly, as early as 1958, computer scientists were showing particular interest in the extraction and classification of unstructured text. But these were just scientific disputes. Unstructured data entered the mainstream a dozen or so years ago. At that time, analysts at IDC began to warn of the impending avalanche of unstructured data. Their predictions proved to be accurate. It is estimated that they currently account for around 80% of unstructured data, and even 95% in the case of Big Data sets. Their amount doubles every 18-20 months.
Structured and Unstructured Data
Aron Mohit, founder of Cohesity, compared data to a large iceberg, with structured data at the top, protruding from the surface of the water, and the rest being what is not visible. Unstructured data is found almost everywhere: in local server rooms, the public cloud, and on end devices. They do not have a predefined structure or schema, they exist in various formats, often occur in a raw and unorganized state, can contain a lot of information, which makes them usually difficult to manage. The lack of structure and a standardized format makes them difficult to analyze. Examples of unstructured data include texts such as emails, chat messages, and written documents, as well as multimedia content such as images, audio recordings, and videos.
Somewhat in the shadow of unstructured data are structured data. As the name suggests, they are organized and arranged in rows and columns. The structured format allows for their quick search and use, as well as high performance of operations. Although structured data represents only the tip of the iceberg, its role in business remains invaluable. They are commonly found in financial documentation in the form of transaction records, stock market data, or financial reports. Structured datasets are crucial for analyzing market trends, assessing investment risk, and facilitating financial modeling. They also play a significant role in healthcare. Organized patient documentation, diagnostic reports, and medical histories help ensure continuity of patient care and support medical research. Among e-commerce companies, structured data includes product catalogs, customer purchase histories, and inventory databases. With this information, marketers can implement personalized marketing strategies or better manage customer relationships.
Protecting Unstructured Data
Staying with Aron Mohit’s parallel, unstructured data is the invisible part of the iceberg, hiding many surprises. It includes many different types of information, such as Word documents, Excel spreadsheets, PowerPoint presentations, emails, photos, videos, audio files, social media, logs, sensor data, and IoT data. Unfortunately, the mountain continues to grow. And it is precisely the avalanche-like growth of data, as well as its dispersal, that poses considerable challenges for those responsible for its protection.
On NAS servers, in addition to valuable resources, there is a lot of unnecessary information, sometimes referred to as “zombie data”. Storing such files reduces system performance and unnecessarily generates costs, which translates into the need for more arrays or wider use of mass storage in the public cloud. According to Komprise, companies spend over 30% of their IT budget on storage.
Unnecessary files should be destroyed or archived, e.g., on tapes, if required by regulations. This has never been an easy task, and with the boom in artificial intelligence, it has become even more difficult. Organizations are collecting more and more data, on the assumption that it may be useful for training and improving AI models.
It should also be borne in mind that unstructured data sometimes contains sensitive information, e.g., about health or allowing the identification of specific individuals. Finding them is more labor-intensive than in the case of structured data, due to the loose format. However, the organization must know what they contain in order to locate them quickly if necessary.
A separate issue is the progressive adaptation of the SaaS model. In this case, service providers do not guarantee full protection of data processed by cloud applications. As a result, service users must invest in special tools to protect SaaS. As you can easily guess, vendors provide solutions for the most popular products, such as Microsoft 365. But according to the “State of SaaSOps 2023” report, the average company used an average of 130 cloud applications last year. It is easy to imagine the chaos, and therefore the costs, if an organization had to implement a separate tool for at least half of the SaaS used.
Protecting Structured Data
At first glance, everything seems simple, but the devil is in the details. The choice of the appropriate methodology usually depends on two factors: frequency, data quantity, and the amount of data changes. In the first case, critical databases typically require multiple backups created daily, while for less critical ones, a backup performed every 24 hours or even once a week may suffice.
Another issue is the amount of data. The administrator balances between three options to avoid overloading the network bandwidth or filling up server disks. The most common method involves creating a full copy of the entire database, including all data files, database objects, and system metadata. In case of loss or damage, a full backup allows for easy restoration, providing comprehensive protection. This method has two drawbacks: it generates large files, and creating copies and restoring the database after a failure takes a considerable amount of time.
Therefore, for backing up large databases, the incremental option seems better. This method involves saving changes made since the creation of the last full backup. This method does not require a lot of disk space and is faster compared to creating full backups. However, recovery here is more complex because it requires both a full backup and the latest incremental backup.
Another option is transaction log backup. The process involves recording all changes made to the database through transaction logs since the last transaction log backup. This method allows restoring the database to the exact moment before the problem occurred, minimizing data loss. The disadvantage of this method is the relatively difficult management of backup copies. Additionally, full transaction log backups are required for restoration.
Nowadays, when everything needs to be available on demand, companies are moving away from archaic methods that require shutting down the database engine during backup. New solutions allow creating a backup copy of all files located in the database, including table space, partitions, the main database, transaction logs, and other related files for the instance, without shutting down the database engine.
Protecting NoSQL Databases
In recent years, NoSQL databases have grown in popularity. As the name suggests, they do not use Structured Query Language (SQL), the standard for most commercial databases such as Microsoft SQL Server, Oracle, IBM DB2, and MySQL.
The biggest advantages of NoSQL, such as horizontal scalability and high performance, make them suitable for web applications and applications containing large amounts of data. However, these advantages translate into difficulties in protecting applications. A typical NoSQL instance supports applications with a very large amount of rapidly changing data. In such a case, a traditional snapshot is not suitable. Additionally, if the data is corrupted, the snapshot will restore the corrupted data. Another serious problem is the lack of NoSQL compliance with the ACID principle (Atomicity, Consistency, Isolation, Durability), unlike conventional backup tools. As a result, it is impossible to create an accurate “point-in- time” backup copy of a NoSQL database.
Conclusion
Multi-point solutions with various interfaces and isolated operations make it impossible to obtain a unified view of the backup infrastructure and manage all data located in the on-premises environment, public clouds, and the network edge. There are strong indications that the future of data protection and recovery solutions will be dominated by solutions that consolidate many point products into a platform managed through a single user interface. Customers will increasingly look for systems that offer scalability and support a comprehensive set of workloads, including virtual, physical, cloud-native applications, traditional and modern databases, and storage.
For those seeking a comprehensive backup and recovery solution for both structured and unstructured data, Storware Backup and Recovery stands out as a top choice. Its versatility goes beyond basic file backups, offering features like agent-based file-level protection for granular control, hot database backups to minimize downtime, and virtual machine support for a holistic data protection strategy. This flexibility ensures your critical business information, whether neatly organized databases or creative multimedia files, is always secured with reliable backups and efficient recovery options.
Modernizing Legacy Backup Solutions
Traditional legacy backup solutions served organizations in the past. However, in recent years, they have been unable to keep up with data protection needs and the rapid increase in cyber threat sophistication. Thus, any organization still relying on legacy backups should be prepared to encounter data loss because of the inefficiency of these outdated solutions.

To keep their businesses on track, organizations must upgrade to modernized backup solutions that are on par with the realities of data threats today, ensuring optimal protection from data loss and speedy recovery during a data disaster. This article explores the failures of legacy backup solutions and the growing need for organizations to upgrade to modernized solutions that offer better protection.
What is Backup Modernization?
Backup modernization is the process of replacing an outdated data protection solution with a newer backup and recovery system. Modern backup provides better technological advantages, providing more effective and efficient protection against data disasters. With the ever rising data threats, upgrading your backup solution is crucial for business continuity.
Failures of Legacy Backup Solutions
Organizations often get stuck with legacy data protection systems because they are already familiar with these systems. Some also shy away from the imminent cost needed to overhaul these systems. However, the truth is that these legacy backup solutions are outdated and will present several issues you can avoid when you upgrade to modern backup systems. Some problems legacy solutions pose are:
- Expensive Use and Maintenance
Maintaining legacy systems could be very expensive because of their complexity and the need for specialized knowledge of these solutions. Thus, running legacy systems will incur unnecessary costs for your organization.
- Long Backup Windows
Also, legacy solutions lead to higher downtime because they take time to recover data. A typical backup system has lengthy backup windows, meaning data could get lost if a disaster occurs between one backup process and another. This lack of incremental backups leads to slow processing and higher data loss or corruption risks.
- Disaster Recovery Challenges
Besides backup, disaster recovery is another crucial concern regarding data protection. After a data disaster, the quick recovery of data ensures an organization returns to its regular operation in record time. However, legacy solutions take time to restore data and are less reliable, posing greater risk when disasters occur.
- Delayed Cloud Adoption
Most legacy systems don’t support clouds because they were not built with it in mind. Thus, it becomes difficult to integrate cloud solutions, preventing organizations from using cloud infrastructure to their advantage.
- Scalability Issues
Legacy systems often struggle to scale because they are designed primarily for smaller, static datasets. As a result, they may be unable to handle large data volumes, making them unsuitable for growing organizations that constantly face increasing data volumes.
- Lack of Advanced Security features and Automation
Operating legacy backup systems requires more human resources because they need manual operations. These traditional solutions don’t offer automatic security features like encryption and access control. So, there is a higher risk of human error and an increased hands-on management of resources.
Why Organizations Should Upgrade Their Legacy Backup Solutions
With legacy backup solutions proven less effective and efficient, looking into other options is crucial. The best solution companies can seek is to upgrade from legacy solutions to modernized backups that offer better results. Let’s look at some reasons why organizations should upgrade their systems.
- Improved Speed and Efficiency
Legacy systems can be complex, and the lack of automation and advanced features contributes to their failing speed and efficiency. However, modernized solutions prioritize speed and efficiency, leveraging advanced technologies, including incremental backups, continuous data protection (CDP), and deduplication. These features help to reduce downtime by backing up and restoring data quickly.
- Automation
Modern solutions use automation to reduce the manual workload, ensuring the data protection process runs smoothly. They offer scheduled backups, central management, and automated failover. Unlike legacy systems that require a more hands-on approach, modernized backup solutions streamline the work process, helping companies achieve better results.
- Enhanced Data Security
The main aim of backup solutions is data protection, but legacy systems may fail to provide the best security because they weren’t designed with the latest threats in mind. Thus, they are less effective in fighting against modern cyber threats. On the other hand, modern backup solutions consider the present sophistication of cyber threats. So, these solutions integrate the latest security features to offer more robust data backup and recovery, reducing the risk of data corruption and loss and ensuring quick data recovery.
- Scalability
In any growing organization, scalability is essential. While legacy systems find it challenging to scale alongside the organization’s growing needs, data volume keeps growing. So organizations must find a solution that can quickly adapt to this ever-increasing need and work speed. Modern backup solutions are scalable, ensuring that organizations have no issues with data protection as the company size and data volume grows. This leads to flexibility and reduced costs over time.
- Cloud Integration
Cloud has become a staple in today’s data world, offering increased data protection and less dependence on physical infrastructure for organizations. Cloud integration not only improves data protection but also reduces the cost of operation by limiting the physical infrastructure needed to protect data. Modernized backup solutions integrate Cloud, enabling organizations to combine physical and virtual data storage and protection for optimal results and lower risks.
- Support for Latest Technologies
Legacy solutions may not support newer technologies as most are not open to technological advancements. However, modernized solutions support state-of-the-art technologies like containerization, continuous data protection (CDP), and deduplication, ensuring they offer data protection at its peak.
Conclusion
Legacy backups can no longer serve organizations because they pose problems like scalability issues, disaster recovery challenges, long backup windows, expensive maintenance, and a lack of advanced security features and automation. These challenges prevent them from providing the best protection against data threats or an excellent recovery process.
Companies must upgrade to modernized backup solutions that offer improved speed and efficiency, automation, scalability, enhanced data security, and support for the latest technologies. This will ensure that their data protection system can weather against cyber threats and other data disasters.
Storware Backup and Recovery bridges the gap between modern and legacy data management. For modern workloads, it offers features like agent-based protection for cloud data, containers, and virtual environments, ensuring your most cutting-edge applications are secure. However, Storware doesn’t leave older systems behind. It can integrate seamlessly with existing backup solutions, acting as a proxy to streamline and centralize your overall data protection strategy, regardless of the system’s age. This future-proof approach ensures your valuable information is protected, no matter its source or platform.
Automation, Orchestration and Data Protection Efficiency
Growth and development never stop, and this also rings true when it comes to data management technologies. In recent years, automation tools and orchestration platforms have significantly improved, and these advancements help frame and optimize data backup and recovery, enhancing efficiency, speed, and reliability. With advancements in automation tools and orchestration platforms, their benefits have more than doubled, giving organizations a better edge over cyber threats and other potential data disasters.
 This article explores five advancements in recent years and the benefits of automation and orchestration in the backup and recovery process.
This article explores five advancements in recent years and the benefits of automation and orchestration in the backup and recovery process.
This article explores five advancements in recent years and the benefits of automation and orchestration in the backup and recovery process.
Benefits of Automation and Orchestration in Backup and Recovery Processes
1. Consistency and Reliability Automated backup procedures ensure backups are done consistently and reliably at proper intervals, preventing human errors or missed backups. This gives you confidence that your data is consistently protected. 2. Economical Use of Time and Resources Automating backup tasks gives the IT staff free time to concentrate on other, more significant issues than merely routine activities associated with backups. In one turn, these automated solutions will execute the backup and recovery workflows quickly and very effectively. 3. Improved Data Management Choosing to automate backup and recovery employs tools like data deduplication and compression to optimize space usage and minimize costs. A centralized management interface also gives better visibility and control of the status of the backups and storage utilization, ensuring that organizations can monitor and manage the process. 4. Shortened Recovery Times Automated recovery processes will help restore data quickly and reduce business operation downtime if data is lost or there is a system failure. Automated recovery tools can promptly trace and retrieve the necessary data quickly, thus reducing the recovery process to a few minutes from what would have taken hours or even days. This ensures that your organization bounces back and returns to the usual business operation on time. 5. Data Protection An automated backup system, developed using encryption, access controls, and compliance enforcement, will ensure the protection of backup data and guarantee the satisfaction of regulatory requirements. Thus, when using an automated system, you can rest assured that your data is appropriately secured. Incremental backups and continuous data protection also ensure that data doesn’t get lost during disasters. 6. Eliminating Human Related Errors Another risk it eliminates is human-related mistakes. Mistakes such as selecting the incorrect backup files and overwriting vital information could occur during manual recovery processes. Automated tools eliminate these errors by following predefined protocols and procedures, ensuring consistent and proper implementation of the recovery process each time. 7. Scalability With advanced backup tools, companies don’t have to worry about growing data sizes. They can easily back up data and handle storage demands, ensuring all data is sufficiently covered. As the organization grows, accommodating increasing data needs, these advanced solutions scale along with the data size.Five Advancements in Automation Tools and Orchestration Platforms
1. Continuous Data Protection (CDP) A groundbreaking technology called continuous data protection captures every change that happens with data and tracks changes in real-time. Unlike traditional backup, which depends on periodic snapshots, CDP creates an unbroken data stream that organizations can use instantly in recovery. It guarantees restored data up to any point and minimizes data loss and downtime. 2. AI-powered Backup Optimization Now, backup processes are optimized using artificial intelligence and machine learning algorithms. By analyzing historical data and patterns, these technologies can single out redundant or unnecessary backups, reuse them, optimize storage usage, and even automate data retention and deletion. This doesn’t just help drive greater efficiency; it also reduces overall storage costs. 3. Cloud-Native Backup Solutions With the advent of cloud computing, cloud-native backup solutions can leverage their scalability, flexibility, and cost-effectiveness. Most of these solutions are directly tied to leading cloud platforms and typically feature automated scheduling for backups, off-site replication, and instant recovery. Unlike the on-premises hardware necessary for many cloud services, a cloud-native backup solution streamlines infrastructure management while taking some of the responsibility off the IT team. 4. Orchestrated Disaster Recovery These days, disaster recovery processes are much easier and more automated because of orchestration platforms. This allows organizations to redefine the DR (disaster recovery) workflows they must configure during a disaster. It orchestrates task execution, such as failover, failback, and testing, to ensure consistent and reliable recovery procedures. Orchestration of DR reduces complex management in the DR infrastructure, improving overall resilience. 5. Self-healing Data Protection Some modern backup and recovery solutions can now self-heal. These systems can detect and automatically correct data corruption, missing backups, or configuration errors. With constant monitoring of the backup infrastructure, self-healing technology ensures robust data protection continuously, even after unexpected failures or human errors.The Future Of Virtualization Infrastructure
When the Broadcom company announced its acquisition of VMware on the 26th of May 2022, the virtualization industry was brazing for another great evolution. And this time, we might witness a greater blast in the evolution of virtualization infrastructures. So, at the back of this announcement and the introduction of many virtualization-enhancing features, are we getting into the fourth-age evolution of virtualization infrastructures?

The inception of data virtualization infrastructures focused on relieving the huge task accompanying big data issues of physical machines by granting end-users the opportunity to access and modify data stored across various systems through a single view. Using the ESX hypervisor machine, VMware gained huge momentum in the data management sector. However, while this infrastructure was widely accepted, it contains a series of challenges that made users desire significant improvement.
At the back of this development, the second age of virtualization infrastructures comes into play. This time, a cloud-based data virtualization infrastructure was announced, taking virtualization to a new level where users can access data on popular platforms like Azure, Amazon web, and more. Again, this transition gave users timely access to the database with minimum stress. Then, big companies and the public sector with a data center utilized OpenStack for data positioning. Thus, increasing their accessibility to end users.
The Third virtualization infrastructure age introduced the use of containers in database management on Kubernetes. This transformation aims to allow developers to present their database in independent containerized microservices. Thus, they can promote their services to test, stage, and promotion environments and become readily available to users.
Utilizing ETCD, Kubernetes stores the containerized services, which are only accessible with the help of an API. This development was a big upgrade on the seemingly cumbersome traditional VMs and Hypervisors as it provides users with the needed database at the minimum interval. While data virtualization keeps enjoying a series of upgrades, we might as well say that we are already witnessing the fourth age of evolution. This development makes users curious about what the fourth evolution has in stock and about what the future holds for data virtualization.
So, before moving on to the future of virtualization infrastructures, let’s look at what the buzzing fourth-age evolution is all about and why this development is all for the customer’s good.
The fourth age virtualization infrastructures
Like every other evolution mentioned earlier, the fourth age virtualization comes with another view on virtualization. It is also called the age of evolution and convergence on cloud-native platforms. It aimed at running virtual machines alongside Kubernetes through the help of KubeVirt. The KubeVert project allows KVM-enabled machines to be managed as pods on Kubernetes.
Despite the fame of Kubernetes in recent years, it’s surprising that many projects are still run on virtual machines. With the prolonged coexistence between these two virtualization tools, the new evolution is about having both works as a single system without a requirement for the actual application.
This innovation combines the features of both Virtual machines and Kubernetes to provide a good user experience. In addition to this benefit, KubeVirt grants Virtual machines the opportunity to utilize Kubernetes abilities, as seen with projects like Tetkton, Knative, and the like. These projects work as both Virtual machines and container-based applications.
Features of the fourth age evolution Virtualization Infrastructures
Combining virtual machines and containers into a single system, the fourth-age virtualization tools possess several amazing features that provide a great user experience. Here are the features:
- Virtualization Monitoring
- Pipelines Incorporations
- Utilization of GitOps
- Serverless Architecture
- Service Mesh
Virtualization Monitoring
This is an automated and manual technique that ensures appropriate analysis and monitoring of virtual machines and other virtualization infrastructures. The virtualization monitoring technique has three main processes that enhance its efficacy. This process includes monitoring, troubleshooting, and reporting. This feature guides against untoward occurrences, performance-related issues, unexplainable or architectural changes, and risks.
Also, it allows you to plan capacity better and manage resources adequately. Another benefit associated with virtualization monitoring is the absence of server overload, which makes data processing faster and better. Lastly, virtualization monitoring improves the general performance of virtualization infrastructures by quickly detecting impending issues. With total control of virtualization monitoring processes, a feature seen in previous ages, virtualization monitoring is a key feature in the new infrastructures with more efficiency.
Pipelines Incorporations
Pipelines are aggregates of tasks assembled in a defined order of execution through the help of pipeline definitions. With this feature, a continuous flow integration and delivery of your applications’ CI/CD workflow become organized.
OpenShift Pipeline, based on Kubernetes resources, is an example of how this feature works. In addition, it utilizes Teckton for optimum accuracy. With CI/CD pipeline automation, you can easily escape human errors and maintain a consistent process for releasing software.
Utilization of GitOps
GitOps aims at automated processing, ensuring secure collaboration among teams across repositories. This feature utilizes Git for applications and infrastructure management. GitOps allows for maximum productivity through its ability to offer continuous deployment and delivery. Also, it allows you to create a standardized workflow using a single set of tools.
Furthermore, GitOps provides more reliability through the revert and fork feature. There’s also the provision of additional visibility and fewer attacks on your server. GitOps provides easier compliance and auditing due to the ability of Git to track and log changes. Git also affords users an augmented developer experience while managing Kubernetes updates, even as a newbie to the Kubernetes services.
Serverless Architecture
Serverless computing is an as-used backend service provision method that ensures users face less stress while computing databases. In addition, it allows users to work on a budgeted amount as the user only pays for what they consume. Also, the scalability of this feature makes it possible to process many requests in less time. You can easily update, fix or add a new feature to an application with minimal effort. Moreover, the serverless architecture significantly reduces liabilities as there’s no backend infrastructure to account for.
Lastly, with serverless architecture, efficiency is hundred percent because there’s no idle capacity, as it is usually evoked only on request.
Service Mesh
A feature that uses a sidecar to control service-to-service communication over a network. Service mesh allows different parts of an application to work hand in hand. This feature is commonly seen in microservices, cloud-based applications, and containers. With the service mesh feature, you can effectively separate and manage service-to-service communication in your application. Also, detecting communication errors becomes easier because each exists on an individual infrastructure layer.
Furthermore, the service mesh offers security features such as authorization, encryption, and authentication. As a result, application development, testing, and deployment also become faster. Lastly, having a sidecar beside a cluster of containers is good for managing network services. With this and other amazing features of the fourth-age evolution virtualization, you can incorporate your VMs and containers into a cloud-native platform.
How can you incorporate cloud-native platforms into your business?
While you might be wondering how to get started with a cloud-native platform, the simplest thing to do is research the essence of using Kubernetes and containers and how you can incorporate them into your business. Furthermore, you can also look into organizations running a similar business as you and how they use the cloud-native platform. Then, after understanding how this platform works and how you can transition into the platforms, proceed to download the Red Hat OpenShift.
Install the application, and after the installation, you can download the OpenShift Migration Toolkit for Virtualization. This Toolkit is a guide for efficiently transitioning into the OpenShift Virtualization from the current virtual machines. With this development, you can incorporate your virtual machines into the current Kubernetes. Also, virtual machines will be able to offer OpenShift capabilities such as cluster management, cloud storage, cloud-native platform services, and other amazing features.
Just as the transition from the big old data to the growing virtualization era, virtual machines are fast becoming a thing of the past and should be replaced by more efficient cloud-native platforms. Moreover, with the growing demand for data sharing in the digital world, sticking with an old-time virtualization system might impact your business negatively. Therefore, you need to embrace this latest trend for maximum output.
What does the future hold for virtualization infrastructures?
Looking at how far virtualization infrastructures have changed over the years, it’s safe to say that more exciting features await the evolution of virtualization infrastructures. The digital world keeps expanding with jaw-dropping developments in all sectors. Moreover, cryptocurrency has come to challenge the legal notes for making digital transactions, with robots gradually replacing human efforts, among other innovations.
So, the wave in the evolution of virtualization infrastructures is expected to become stronger over the years. Soon enough, we might expect the innovation of the fifth-age virtualization infrastructures.
Backup and Restore OpenStack Volumes and Snapshots with Storware
Storware Backup and Recovery offers a comprehensive solution for protecting your OpenStack environment.

Here’s a step-by-step guide to get you started with backups and recovery:
Prerequisites:
- OpenStack environment using KVM hypervisor and VMs with QCOW2 or RAW files.
- Storware Backup and Recovery software.
Deployment:
1. Install Storware Backup and Recovery Node: The Storware node can be installed on a separate machine. Ensure it has access to OpenStack APIs and hypervisor SSH.
2. OpenStack API Integration: Configure Storware to communicate with OpenStack APIs like Nova and Glance for metadata collection and VM restore processes.
Backup Configuration:
1. OpenStack UI Plugin (Optional): Install the Storware OpenStack UI plugin to manage backups directly from the OpenStack dashboard. This simplifies backup creation, scheduling, and restores.
2. Backup Schedules: Define backup schedules for your VMs. Storware supports both full and incremental backups.
3. Backup Options:
- Libvirt strategy
- Disk attachment strategy
- Ceph RBD storage backend
All three strategies support full and incremental backups.
Libvirt strategy works with KVM hypervisors and VMs using QCOW2 or RAW files. It directly accesses the hypervisor over SSH to take crash-consistent snapshots. Optionally, application consistency can be achieved through pre/post snapshot command execution. Data is then exported over SSH.
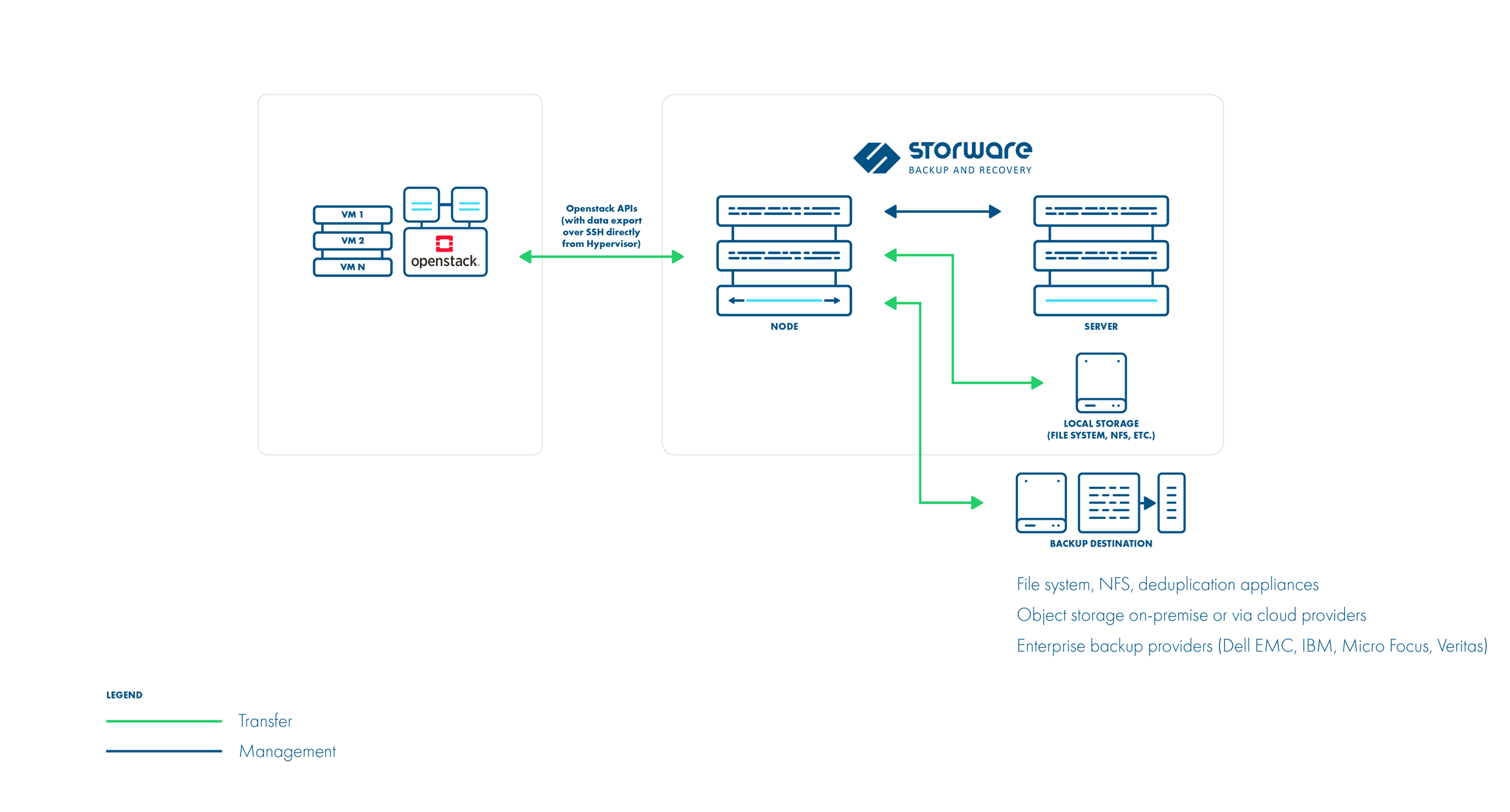
Disk attachment strategy is used for OpenStack environments that use Cinder with changed block tracking. It uses a proxy VM to attach disks to the OpenStack instances. Snapshots are captured using the Cinder API. Incremental backups are supported. Data is read from the attached disks on the proxy VM.

Ceph RBD storage backend
Storware Backup & Recovery also supports deployments with Ceph RBD as a storage backend. Storware Backup & Recovery communicates directly with Ceph monitors using RBD export/RBD-NBD when used with the Libvirt strategy or – when used with the Disk-attachment method – only during incremental backups (snapshot difference).
Libvirt strategy

Disk attachment strategy

Retention Policies: Set retention policies to manage how long backups are stored.
Backup Process:
1. Storware interacts with OpenStack APIs to gather VM metadata.
2. Crash-consistent snapshots are taken directly on the hypervisor using tools like virsh or RBD snapshots.
3. (Optional) Pre-snapshot scripts run for application consistency.
4. VM data is exported using the chosen method (SSH or RBD).
5. Metadata is exported from OpenStack APIs.
6. Incremental backups leverage the previous snapshot for faster backups.
Recovery Process:
1. Select the desired VM backup from the Storware interface.
2. Choose the recovery point (specific backup version).
3. Storware recreates VM files and volumes based on the backup data.
4. The VM is defined on the hypervisor.
5. Disks are attached (either directly or using Cinder).
6. (Optional) Post-restore scripts can be run for application-specific recovery steps.
Additional Notes:
- Storware supports both full VM restores and individual file/folder recovery.
- The OpenStack UI plugin provides a user-friendly interface for managing backups within the OpenStack environment.
- Refer to Storware documentation for detailed configuration steps and advanced options -> https://storware.gitbook.io/backup-and-recovery
By following these steps and consulting the Storware documentation, you can leverage Storware Backup and Recovery to safeguard your OpenStack VMs and ensure a quick recovery process in case of data loss or system failures.